
When Agentic AI Fails: 7 Recovery Strategies from Real Deployments
Agentic AI isn’t fail-proof. Discover 7 proven recovery strategies from Elevin Consulting that leaders trust to manage failures and build resilient AI systems.
Aishwarya
11/1/20258 min read


You’ve invested in Agentic AI: systems designed not just to follow commands but to think, plan, and act across complex workflows. The promise was bold: greater efficiency, lower costs, faster decisions, and new revenue opportunities.
But then it happens.
An agent gets stuck in a decision loop.
Another misreads a client email.
A third relies on outdated data and takes the wrong action.
Suddenly, your cutting-edge automation feels less like an innovation and more like an unpredictable liability.
Sound familiar? You're not alone. Failure isn't a sign that Agentic AI is flawed; it's an inherent part of deploying advanced, reasoning systems. In fact, up to 85% of AI projects fail to meet expectations, often due to poor data quality or insufficient relevant data
The real differentiator between a costly experiment and a successful AI deployment isn’t avoiding failure; it’s recovering intelligently.
The most resilient organizations aren’t the ones that never see errors, but the ones that detect, contain, and adapt before failures spiral into disruption.
At Elevin Consulting, we’ve seen both sides of Agentic AI: the promise and the pitfalls. Drawing from real deployments and client implementations, this guide breaks down seven proven recovery strategies to help you turn AI setbacks into sustainable, self-correcting systems.
Why Do Agentic AI Systems Fail? The Common Breakdown Points
Before we fix the problems, we need to diagnose them. Agentic AI systems fail for reasons that are often different from traditional, single-task AI models. Their complexity is their strength and their primary vulnerability.
Here are the five most common breakdown points observed in real deployments:
1. Data Drift and Quality Decay
Over time, data that once trained an agent becomes outdated or irrelevant.
For instance, an inventory optimization agent trained on pre-pandemic supply patterns may continue applying obsolete assumptions, leading to inefficiencies or incorrect forecasts.
Impact: Reduced decision accuracy, silent drifts, and degraded ROI.
2. Goal Misalignment
Agents optimize for what they’re told, not always what the business intends.
If the optimization goal prioritizes “maximum response rate,” a support agent might spam users instead of improving satisfaction.
Impact: Business misalignment, poor customer experience, and wasted automation cycles.
3. Systemic Overdependence
When multiple agents are linked without clear fail-safes, a single agent’s malfunction can cause cascading system-wide failures.
This is common in logistics, manufacturing, and fintech ecosystems with layered dependencies.
Impact: Chain reactions across departments or processes.
4. Adversarial Inputs and Security Blind Spots
Agents that interact with open environments, like chatbots or data-scraping agents, are vulnerable to malicious prompts or poisoned data injections.
Impact: Security breaches, data leaks, and reputational damage.
5. Lack of Human Oversight
Autonomy doesn’t mean absence of governance. Many early adopters deploy agents without continuous monitoring, interpretable analytics, or escalation frameworks.
Impact: Small anomalies escalate into major operational disruptions before detection.
In short: Agentic AI failures often occur not because agents are “too autonomous,” but because their autonomy outpaces the organization’s readiness to govern and recover.
Now that we’ve identified the root causes, let’s examine the seven recovery strategies that leading enterprises use to bounce back fast when their AI agents go off-track.
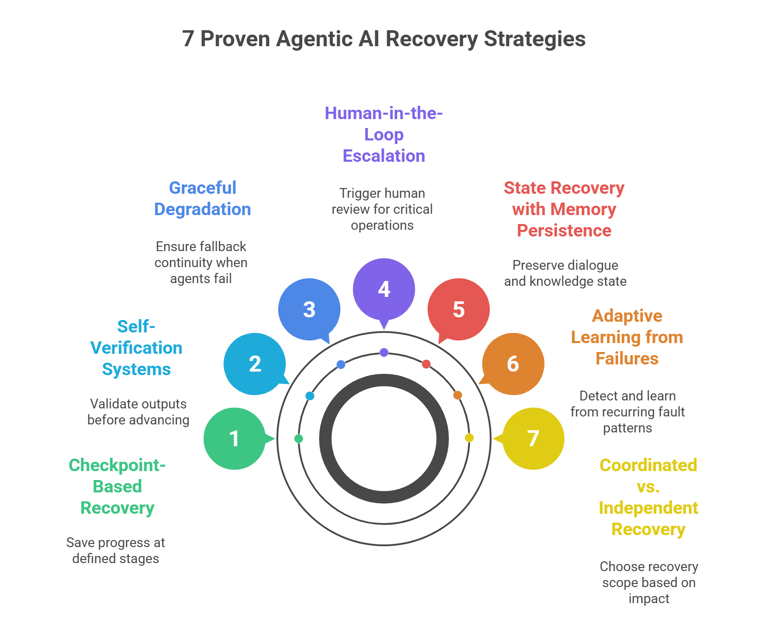
1. Implement Checkpoint-Based Recovery for Multi-Step Workflows
The Problem: Your AI agent is halfway through a complex 10-step process when something goes wrong. Starting from scratch wastes time, money, and computational resources.
The Solution: Save checkpoints after each successfully completed step, allow plan rewinding to the most recent checkpoint, and store side effects in reversible formats like git stashes or temp files to enable time-efficient recovery while preserving determinism in workflow execution.
Real-World Application:
Code generation agents: Save code changes at each stage so you can roll back to the last working version
Data pipeline agents: Checkpoint after each transformation step in ETL processes
Infrastructure deployment agents: Create restore points before each configuration change
Implementation Tip: Design your checkpoints to be immutable and timestamped. Include enough context so the agent can understand where it was and what it was trying to accomplish.
Business Impact: Reduces recovery time from hours to minutes and prevents costly resource waste from restarting complex processes.
2. Build Self-Verification Systems with Output Validation
The Problem: Silent failures that would otherwise be undetected can propagate through your entire system, causing compound errors where every subsequent step builds on a faulty premise.
The Solution: Implement automatic output verification before allowing results to move to the next stage.
Real-World Application:
Schema validation: Before passing data to the next agent, verify it matches expected formats
Semantic checks: Use a secondary AI model to review outputs for logical consistency
Constraint verification: Ensure outputs respect business rules (e.g., prices are positive, dates are in the future)
Example Implementation:
1. Agent generates customer invoice
2. Validation layer checks:
- All required fields present
- Calculations are correct
- Totals match line items
- Customer data is valid
3. If validation fails → trigger recovery protocol
4. If validation passes → proceed to next step
Business Impact: Catches errors before they affect customers or downstream processes, maintaining data integrity and system trust.
3. Design Graceful Degradation with Fallback Mechanisms
The Problem: Your primary AI agent encounters a scenario it can't handle. Without fallbacks, the entire workflow stops, frustrating users and halting operations.
The Solution: Use bounded autonomy with clearly defined limits on what actions an AI agent can take without confirmation, cached results from previously validated outputs when fresh processing isn't possible, and practical fallbacks.
Real-World Application:
Customer service chatbots: If the AI can't resolve an issue, seamlessly escalate to a human agent with full context
Content recommendations: Fall back to popularity-based recommendations when personalization models fail
Data processing: Use the last known good configuration when real-time processing encounters errors
Tiered Fallback Strategy:
Primary: Full AI agent autonomy
Secondary: AI with increased human oversight
Tertiary: Rule-based automation
Final: Human takeover with full context transfer
Business Impact: Ensures continuity of service even during AI failures, maintaining customer satisfaction and operational efficiency.
4. Establish Human-in-the-Loop Escalation Protocols with Ethical Guardrails
The Problem: Some failures are ambiguous. The agent isn't sure if it's on the right track or if the stakes are too high to proceed without validation. Even more critical: AI agents can make decisions that seem technically correct but violate ethical boundaries, compliance requirements, or brand values.
The Solution: For tasks involving code modification, infrastructure changes, or cost-heavy operations, agents should escalate failure paths to a human reviewer when confidence is low or failure persists, integrating preview diffs, plan visualizations, or logs into the UI for human inspection. Critically, implement ethical guardrails that automatically trigger human review for decisions with moral, legal, or reputational implications.
When to Escalate:
Confidence score below threshold (e.g., <70%)
Operations affecting critical systems or large financial amounts
Contradictory information from multiple sources
Ethical boundary triggers: Decisions involving protected classes, sensitive personal data, or discriminatory outcomes
Regulatory or compliance concerns: GDPR, HIPAA, financial regulations, or industry-specific requirements
Bias detection: When outputs show potential demographic bias or unfair treatment patterns
Repeated failures on the same task (3+ attempts)
Brand risk scenarios: Content or decisions that could damage reputation or customer trust
Ethical Guardrail Framework:
Pre-defined boundaries: Establish clear ethical limits before deployment (e.g., never make hiring decisions without human review, always disclose AI involvement in customer interactions)
Bias monitoring: Continuously scan outputs for demographic disparities or unfair patterns
Explainability requirements: Ensure AI can explain its reasoning, especially for high-stakes decisions
Compliance checks: Automated validation against regulatory requirements before executing sensitive actions
Audit trails: Log all decisions with ethical implications for transparency and accountability
Best Practices:
Provide context: Give humans everything they need to make informed decisions quickly
Suggest options: Present the human with 2-3 potential paths forward, flagging ethical considerations for each
Learn from interventions: Track human corrections to improve future agent performance and refine ethical boundaries
Set SLAs: Define maximum escalation response times to prevent workflow bottlenecks
Regular guardrail reviews: Update ethical boundaries quarterly based on new regulations, incidents, or stakeholder feedback
Real-World Application:
HR/Recruitment agents: Flag any candidate screening that shows demographic patterns requiring human review
Customer service agents: Escalate decisions involving customer complaints about discrimination or unfair treatment
Content generation agents: Block or flag content that could be offensive, misleading, or off-brand
Financial agents: Require human approval for any decision that could violate fair lending or anti-discrimination laws
Business Impact: Prevents catastrophic errors and ethical violations while building organizational trust in AI systems through transparent human oversight. Protects against regulatory penalties (EU AI Act fines up to €35M or 7% of global revenue), reputational damage, and customer trust erosion.
5. Implement State Recovery with Memory Persistence
The Problem: When an AI agent fails, it loses conversation history, learned preferences, and specialized knowledge that can't be restored with a simple restart.
The Solution: Implement regular state snapshots, creating recoverable checkpoints of system state, transaction-based operations ensuring complex operations either complete fully or roll back, and incremental learning protection safeguarding newly acquired knowledge against corruption or loss.
Architecture Components:
Conversation state: Store dialogue history, user preferences, and session context
Knowledge state: Preserve learned information and updated beliefs about the environment
Execution state: Track current task, completed steps, and pending actions
External state: Monitor connected systems and data sources
Recovery Process:
1. Detect failure
2. Load most recent valid state snapshot
3. Verify external environment hasn't changed significantly
4. Resume from last confirmed checkpoint
5. Re-validate outputs before proceeding
Business Impact: Maintains continuity in customer interactions and preserves valuable learned behaviors, improving user experience and reducing redundant work.
6. Build Adaptive Learning from Failure Patterns
The Problem: Your agents keep failing in the same ways, but you're not capturing insights to prevent recurrence.
The Solution: Implement failure logging and classification with detailed recording of failure circumstances and types, root cause analysis with automated determination of underlying causes, and adaptive defenses implementing specific countermeasures against previously encountered failures.
Failure Analysis Framework:
Log everything: Capture inputs, outputs, system state, and environmental conditions
Classify failures: API timeouts, data quality issues, logic errors, external service failures
Identify patterns: Which failures occur most frequently? Under what conditions?
Implement fixes: Update prompts, add validation rules, improve error handling
Measure improvement: Track failure rates over time by category
Example Pattern Detection:
If 80% of failures occur with a specific data format → add pre-processing validation
If timeout errors spike during peak hours → implement request queuing
If agents consistently misinterpret ambiguous queries → enhance prompt engineering
Business Impact: Continuously improves system reliability and reduces operational costs through automated learning from mistakes.
7. Deploy Coordinated vs. Independent Recovery Strategies
The Problem: In multi-agent systems, you need to decide whether agents should recover independently or coordinate their recovery efforts.
The Solution: Use coordinated approaches for high-impact failures requiring global state consistency, while local recovery handles routine issues with independent recovery better suited for isolated failures that don't affect global state.
When to Use Coordinated Recovery:
Failures affect shared resources or databases
Multiple agents are working on interconnected tasks
System-wide rollback is necessary
Consistency is more important than speed
When to Use Independent Recovery:
Failures are isolated to a single agent
Speed is critical (high-availability systems)
Agents operate on separate data domains
No global state consistency is required
Hybrid Recovery Strategy: Build decision frameworks that evaluate the scope of failure and system conditions in real-time, enabling the system to select the appropriate recovery strategy without manual intervention, thereby reducing both risk and recovery time.
Business Impact: Balances speed and consistency based on failure context, optimizing both system reliability and performance.
Explore our blog section for in-depth insights and real-world strategies on how leaders across industries are adopting Agentic AI to build smarter, more efficient operations.
Why This Matters for Leaders
For leaders investing in Agentic AI, resilience isn’t a technical metric; it’s a strategic one.
Failures don’t always stem from poor engineering; they often reveal hidden dependencies, goal misalignments, or oversight gaps.
Building resilience means:
Anticipating systemic risks before they scale.
Creating visibility across autonomous layers.
Ensuring humans can intervene when needed.
Turning every breakdown into an improvement cycle.
According to Gartner, 45% of leaders in organizations with high AI maturity keep their AI initiatives operational for at least three years or more, compared to only 20% in low-maturity organizations.
The shift from “fail-safe” to “learn-safe” defines next-generation AI leadership.
Think Agentic AI is too complex to apply? Industry leaders with insights from our eBook “Agentic AI for Business Leaders” are simplifying workflows and gaining back 30+ hours each month. Grab your FREE copy now!
How We Help Build Resilient Agentic Systems
We’ve been through these failures ourselves, and that’s what shaped our approach.
At Elevin, we develop frameworks that help organizations fail smarter: test early, recover faster, and document learning.
Our approach is different:
1. Risk-First Design: We identify potential failure modes before deployment, not after
2. Production-Grade Architecture: Systems built for real-world complexity, not demo environments
3. Continuous Improvement: Failure analysis frameworks that make your systems smarter over time
4. Business-Aligned Metrics: Recovery strategies tied to actual business impact, not just technical indicators
Whether you're planning your first agentic AI deployment or struggling with reliability in existing systems, we can help you build the recovery infrastructure that separates successful implementations from abandoned projects.
Don't wait until your AI project becomes another cancellation statistic.
Book a free discovery call to discuss how we can help you build agentic AI systems that recover gracefully from failures and deliver reliable business value.
Excellence
Elevin Consulting: Your Partner in Growth.
Impact
© 2025 Elevin Consulting Pvt Ltd. All Rights Reserved
Trust
hello@elevinconsulting.com